

优化目标:
优化搜索准确性,提高搜索结果相关性,减少干扰结果,提高内网文章的搜索排名。
优化思路:
一、中文分词优化
优化目标:提升搜索结果的有效性,减少无用结果内容
优化方法:优化分词的准确性、使用智能分词、去掉单字分词结果,启用专用词汇字典、停用词汇字典,后期可以自定义同义词
(一)配置中文分词
使用IKAnalyzer进行中文分词,并启用忽略大小写、配置同义词过滤器:
<!-- IKTokenizer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SynonymFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SynonymFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
</analyzer>
</fieldType>
<field name="content" type="text_ik" multiValued="false" indexed="true" stored="true"/>
<field name="domain" type="text_ik" multiValued="false" indexed="true" stored="true"/>
<field name="title" type="text_ik" multiValued="false" indexed="true" stored="true"/>
<field name="type" type="text_general"/>
<field name="create_at" type="plongs"/>
<field name="update_at" type="plongs"/>
<field name="url" type="string" multiValued="false" indexed="false" stored="true"/>在服务器中确认配置是否已生效:
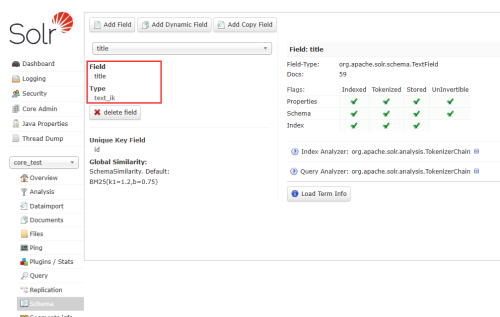
(二)配置自定义词典
1、收集组织专用词汇
如:组织名称、团队名称、项目名称、软件名称、工作过程专用名词等,添加到扩展词典库
2、AI模型提取NLP文本词汇
从已有的文档库中通用AI模型学习,获得一部分组织常用专用词汇,添加到扩展词典库。如:
3、自定义同义词汇
对特有词的同义词进行配置,可以同时查询到相关的同义词结果。
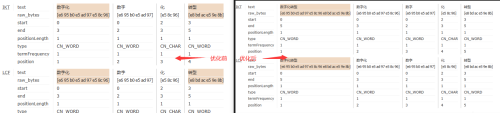
二、查询参数优化
优化目标:提升搜索结果的价值度,优化结果排序
优化方法:调整Solr查询参数配置,使用eDisMax查询解析器替换Lucene默认解析器,优化查询参数,调整字段查询权重,提升特定域名、最近时间段的结果的得分排名。
Lucene查询解析器
Lucene查询解析器语法支持创建任意复杂的布尔查询,但还有一些缺点,它不是用户查询处理的理想解决方案。这里面最大的问题是Lucene查询解析器的语法要求严格,一旦破坏就会抛出异常。指望用户在输入关键词时能够理解Lucene查询语法并始终能输入完美的查询表达式,这显然是不合理的。这意味着,Lucene查询解析器在许多搜索应用中对用户不够友好。
Lucene查询解析器的另一个缺点是它不能默认搜索多个字段。df参数定义了查询解析器默认搜索哪个字段,但是如果想要以不同权重对多个字段进行搜索时,就必须先对查询进行预处理。对大多数Solr开发人员来说,这样的查询预处理工作量过大。为了将用户查询直接传入Solr并优雅地进行处理,扩展的析取最大化查询解析器eDisMax应运而生。
eDisMax查询解析器
eDisMax查询解析器实际上是由Lucene查询解析器和DisMax查询解析器组成。DisMax查询解析器是eDisMax查询解析器的旧版本,只接受关键词和少数几个基本的布尔运算,允许在多个字段中搜索关键词。因为DisMax查询解析器是eDisMax查询解析器的一个子集,所有不建议使用原始的DisMax查询解析器。
虽然eDisMax查询解析器不是Solr的默认查询解析器,但它具有查询语法容错性,不像Lucene查询解析器那样严格。
eDisMax查询参数
eDisMax查询解析器支持Lucene查询解析器的所有查询语法。它们之间只有一个明显差异,eDisMax的输入语法不会抛出异常,而是将无效的输入作为文本字符串进行搜索。它还在语法解析上具有一定的容错性,支持特殊关键词。例如,可以理解小写转换后的AND和OR。这种灵活性和容错性让它比Lucene查询解析器更适合处理用户输入。
(一)调整多个字段的权重
除了安全地处理用户输入文本和自由地解析查询语法,eDisMax查询解析器最有用的一个功能是对多个字段进行搜索。eDisMax查询解析器会将每个内容放在各自的字段中。例如:
q=solr in action&qf=title description author
另外,还可以根据意愿在每个查询基础上调整权重。
q=solr in action&qf=title^1.5 description author^3

(二)调整邻近词项的相关度
eDisMax查询解析器的一个重要功能是调整彼此邻近的词项的相关度。使用Lucene查询解析器的典型查询,不管词项是否彼此邻近,或是否视为一个短语,所有词项的相关度都是一样的。eDisMax查询解析器的另一个功能是,对独立于用户主查询的函数进行任意地相关度调整。
1.pf【短语字段】、pf2和pf3参数
pf参数用于调整那些q参数中所有词项彼此非常靠近的文档得分。pf参数与qf参数使用相同的格式,获取字段列表及可选的相应权重。eDisMax查询解析器尝试对q参数中所有词项进行短语查询,如果能在任何短语字段中找到确切的短语,则对匹配的文档调整相应的权重。
除了pf参数,eDisMax查询解析器还支持pf2和pf3参数。这些参数功能与pf参数类似,不过不需要q参数中所有词项,它们将词项分解为二元【pf2】或三元【pf3】,只对包含少量词项的文档调整权重。例如:在查询Solr finds relevant documents中,pf3参数会对包含短语"solr finds relevant" 或 "finds relevant documents"的文档调整权重。pf2与之类似,对包含其中任意两个连续词短语的文档进行权重调整。
2.ps【短语间隔】、ps2和ps3参数
使用pf参数时,可能不希望查询中的所有词项作为一个精确的短语出现。使用ps参数可以指定查询中的词项间隔位置界限,以此在短语字段上判断匹配情况。eDisMax查询解析器还支持ps2和ps3参数,允许为ps2和ps3修改短语间隔值。不明确指定时默认为ps参数。
3.qs【查询短语间隔】参数
qs参数对用户在主查询q参数上明确指定短语的处理方式类似。将qs参数视为重新定义要匹配的确切内容,可以将间隔默认值为0修改为更高的数值。
4.tie【决胜局】参数
当查询的词项与文档的多个字段匹配时,tie参数可以决定如何处理这种情况。为匹配到的每个字段的每个词项计算其相关度得分,默认情况下,每个文档中得分最高的字段用于该词项的相关度计算。这是析取的最大得分,也是该查询解析器得名“析取最大值”的原因所在。这与Lucene查询解析器形成鲜明对比,Lucene查询解析器通常将每个字段的每个词项的相关度得分相加,计算出每个文档的综合相关度得分。
tie参数决定了最匹配的字段之外的其他字段的词项相关度得分有多少应该贡献给总体相关度得分。tie参数的默认值为0.0,这表示其它字段不贡献权重。当tie为1时,表示贡献全部权重,此时相关等同于Lucene查询解析器。在这种情况下,相关度评分使用的是析取和而不是析取最大值。
5.bq【提升查询】参数
bq参数接受查询字符串,其包含在主查询q参数中,用来影响相关度得分。它不会影响匹配到的文档数,只影响文档返回的顺序。如果想为最近的文档提升相关度,可以在请求中添加一下内容:
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]
这将有效提升日期属于去年的所有文档的相关度得分。另外,还可以指定多个bq参数,在查询解析时针对不同子句分别进行提升。
bq=domain:dataea.cn
6.bf【提升函数】参数
bf参数能够通过函数查询来提升主查询的相关度。例如,提升最新日期的文档的相关度:
recip(rord(date),1,1000,1000)
bf参数接受Solr支持的所有函数及其权重值。
(三)Lucene查询参数说明
1、基本查询
| 参数 | 意义 |
|---|---|
| q | 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=:, |
| fl | 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort |
| start | 返回结果的第几条记录开始,一般分页用,默认0开始 |
| rows | 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页 |
| sort | 排序方式,例如id desc 表示按照 “id” 降序 |
| wt | (writer type)指定输出格式,有 xml, json, php等 |
| fq | (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。 |
| df | 默认的查询字段,一般默认指定。 |
| qt | (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。 |
| indent | 返回的结果是否缩进,默认关闭,用 indent=true |
| version | 查询语法的版本,建议不使用它,由服务器指定默认值。 |
显示简略信息
2、Solr 的检索运算符
| 符号 | 意义 |
|---|---|
| “:” | 指定字段查指定值,如返回所有值: |
| “?” | 表示单个任意字符的通配 |
| “*” | 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号) |
| “~” | 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。 |
| AND || | 布尔操作符 |
| OR、&& | 布尔操作符 |
| NOT、!、- | (排除操作符不能单独与项使用构成查询) |
| “+” | 存在操作符,要求符号”+”后的项必须在文档相应的域中存在² |
| ( ) | 用于构成子查询 |
| [] | 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510] |
| {} | 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510} |
3、高亮
| 符号 | 意义 |
|---|---|
| h1 | 是否高亮,hl=true,表示采用高亮 |
| hl.fl | 设定高亮显示的字段,用空格或逗号隔开的字段列表。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高亮默认字段 standard handler会用df参数,dismax字段用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用hl.requiredFieldMatch选项。 |
| hl.requireFieldMatch | 如果置为true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是false。 |
| hl.usePhraseHighlighter | 如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。 |
| hl.highlightMultiTerm | 如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。 |
| hl.fragsize | -返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。 |
4、分组(Field Facet)
facet 参数字段必须被索引,facet=on 或 facet=true
| 符号 | 意义 |
|---|---|
| facet.field | 分组的字段 |
| facet.prefix | 表示Facet字段前缀 |
| facet.limit | Facet字段返回条数 |
| facet.offict | 开始条数,偏移量,它与facet.limit配合使用可以达到分页的效果 |
| facet.mincount | Facet字段最小count,默认为0 |
| facet.missing | 如果为on或true,那么将统计那些Facet字段值为null的记录 |
| facet.sort | 表示 Facet 字段值以哪种顺序返回 .格式为 true(count)|false(index,lex),true(count) 表示按照 count 值从大到小排列,false(index,lex) 表示按照字段值的自然顺序 (字母 , 数字的顺序 ) 排列 . 默认情况下为 true(count) |
5、分组(Date Facet)
对日期类型的字段进行 Facet. Solr 为日期字段提供了更为方便的查询统计方式 .注意 , Date Facet的字段类型必须是 DateField( 或其子类型 ). 需要注意的是 , 使用 Date Facet 时 , 字段名 , 起始时间 , 结束时间 , 时间间隔这 4 个参数都必须提供 。
| 符号 | 意义 |
|---|---|
| facet.date | 该参数表示需要进行 Date Facet 的字段名 , 与 facet.field 一样 , 该参数可以被设置多次 , 表示对多个字段进行 Date Facet. |
| facet.date.start | 起始时间 , 时间的一般格式为 ” 2015-12-31T23:59:59Z”, 另外可以使用 ”NOW”,”YEAR”,”MONTH” 等等 , |
| facet.date.end | 结束时间 |
| facet.date.gap | 时间间隔,如果 start 为 2015-1-1,end 为 2016-1-1,gap 设置为 ”+1MONTH” 表示间隔1 个月 , 那么将会把这段时间划分为 12 个间隔段 . |
| facet.date.hardend | 表示 gap 迭代到 end 时,还剩余的一部分时间段,是否继续去下一个间隔. 取值可以为 true |
文章作者: DataEA
Views: 157